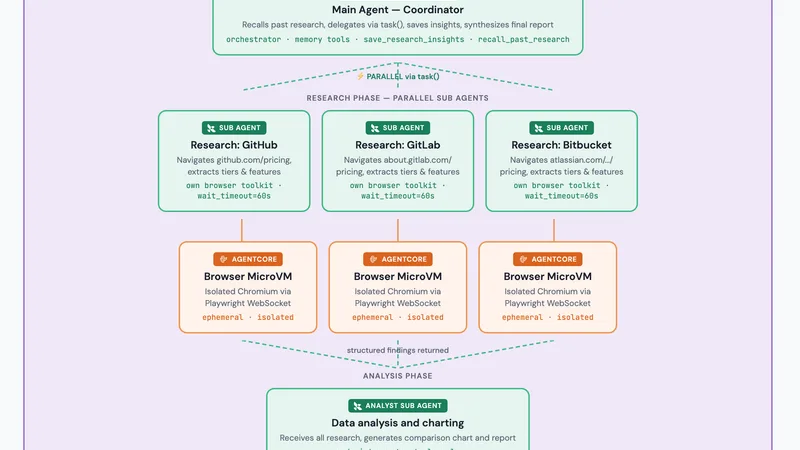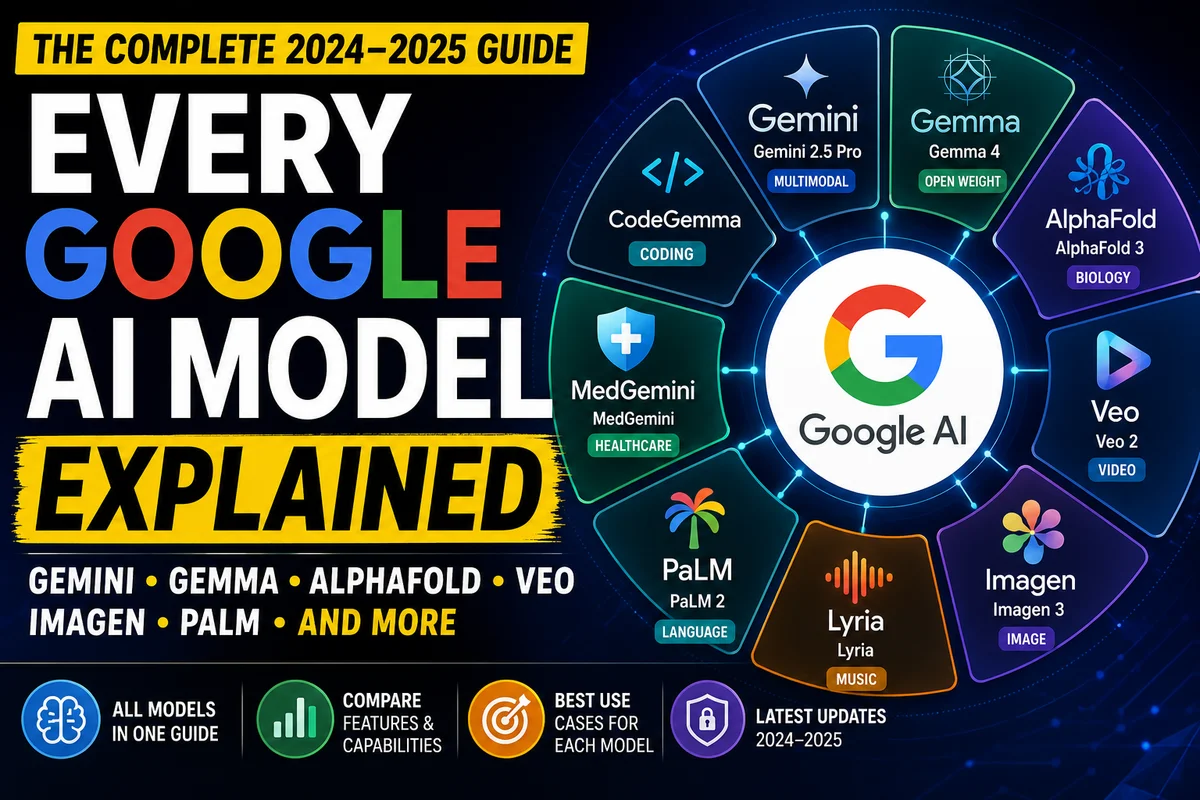
Google has built more AI models than almost any organization on earth — across language, vision, video, music, medicine, and biology. Here is every major model, what it does, how the families differ, and which one belongs in which situation.
Introduction
Google's AI model portfolio is unusually broad. Most companies competing in the AI space have one flagship family. Google has several — a flagship multimodal series called Gemini that spans on-device to frontier capability, an open-weight family called Gemma built for developers who want to run and fine-tune their own models, and a collection of specialized systems covering protein folding, competitive programming, medical diagnosis, video generation, and music composition.
Understanding the full picture requires knowing not just the names but the logic behind each family. This guide covers every Google AI model worth knowing — from the foundational work of BERT and PaLM through to Gemini 2.5 and Gemma 4 — organized so the differences and relationships between them are clear.
How Google Organizes Its AI Models
Before any individual model makes sense, the portfolio needs a frame.
Google's AI work sits primarily under Google DeepMind — the merged entity of Google Brain and DeepMind, formed in 2023. Most new models, research publications, and product deployments originate from this organization.
The model families break into four broad categories:
Gemini — Google's flagship closed proprietary family, ranging from ultra-lightweight on-device models to frontier-level multimodal reasoning systems. These are what powers the Gemini app, Google Search AI features, and Google Workspace AI tools.
Gemma — Google's open-weight family, released under Apache 2.0. These are derived from Gemini research but designed for external deployment, fine-tuning, and self-hosting. Developers can download, modify, and deploy Gemma models commercially without royalty obligations.
Specialized models — Purpose-built systems for specific domains: AlphaFold for protein structure, Veo for video, Imagen for images, Lyria for music, MedGemini for healthcare. These are not general-purpose but represent some of the most significant AI capabilities in their respective fields.
Foundational research models — Earlier systems including PaLM, LaMDA, BERT, and T5 that shaped the current landscape and still power many downstream applications.
Part One: The Gemini Family
The Gemini series is Google's answer to GPT-4 and Claude — a multimodal, continuously evolving family of models designed for the full range of AI applications from mobile to enterprise to frontier research.
The Full Gemini Lineup at a Glance
Model | Generation | Context Window | Key Trait | Best For |
|---|---|---|---|---|
Gemini 1.0 Nano | 1.0 | 32K | On-device, mobile | Pixel devices, local inference |
Gemini 1.0 Pro | 1.0 | 32K | Mid-tier, Bard launch model | General tasks, early Gemini access |
Gemini 1.0 Ultra | 1.0 | 32K | First to beat humans on MMLU | Frontier tasks at 1.0 generation |
Gemini 1.5 Flash | 1.5 | 1,000,000 | Speed plus 1M context | High-volume, latency-sensitive |
Gemini 1.5 Flash-8B | 1.5 | 1,000,000 | Smallest 1.5 model | Highest volume, lowest cost |
Gemini 1.5 Pro | 1.5 | 2,000,000 | First production 1M+ context | Long-document, complex tasks |
Gemini 2.0 Flash-Lite | 2.0 | 1,000,000 | Most cost-efficient 2.0 | High throughput, simple tasks |
Gemini 2.0 Flash | 2.0 | 1,000,000 | Default 2.0 model | Everyday multimodal tasks |
Gemini 2.0 Flash Thinking | 2.0 | 1,000,000 | First Google reasoning model | Math, science, logic |
Gemini 2.0 Pro | 2.0 | 2,000,000 | Strongest 2.0 coding | Advanced coding, long context |
Gemini 2.5 Flash-Lite | 2.5 | 1,000,000 | Smallest 2.5 model | Volume, speed, efficiency |
Gemini 2.5 Flash | 2.5 | 1,000,000 | Best price-performance 2.5 | Balanced tasks with optional reasoning |
Gemini 2.5 Pro | 2.5 | 1,000,000 to 2,000,000 | Google's current frontier model | Hardest reasoning, coding, research |
Gemini 1.0 Series — Where It Began
Gemini 1.0 NanoReleased: December 2023 Context: 32K tokens
The first Google AI model designed to run entirely on a mobile device without a network connection. Gemini 1.0 Nano shipped in two sizes — Nano-1 at 1.8 billion parameters and Nano-2 at 3.25 billion — both running locally on the Pixel 8 Pro. It powers on-device features like Smart Reply in Gboard and summarization in the Recorder app. The significance of Nano is not its absolute capability but what it represents: frontier AI research distilled into a form small enough to run privately on a phone, with no data leaving the device.
Gemini 1.0 ProReleased: December 2023 Context: 32K tokens
The mid-tier Gemini 1.0 model that powered the original Gemini (formerly Bard) chatbot at launch. Gemini 1.0 Pro handled text, images, and code with solid general-purpose performance but was quickly superseded by the 1.5 generation. Its role was primarily to establish the Gemini brand and platform before the more capable successors arrived.
Gemini 1.0 UltraReleased: February 2024 Context: 32K tokens
The flagship of the 1.0 generation and a historically significant model. Gemini 1.0 Ultra was the first AI model to surpass human expert performance on the Massive Multitask Language Understanding (MMLU) benchmark — scoring 90.0% against a human expert baseline of approximately 89.8%. This was the benchmark result that announced Gemini's arrival as a genuine competitor to GPT-4. It is multimodal across text, images, audio, video, and code. The 32K context window was its primary limitation — an issue the 1.5 generation addressed dramatically.
Gemini 1.5 Series — The Context Window Revolution
Gemini 1.5 ProReleased: February 2024 (preview), May 2024 (public general availability) Context: 1,000,000 tokens, later extended to 2,000,000
Gemini 1.5 Pro crossed a threshold that no production model had reached before: a one-million-token context window. To put that in practical terms, one million tokens is roughly 750,000 words — enough to hold an entire book series, a large software codebase, or hours of audio transcription in a single context. Google later extended the available window to two million tokens.
This was not a modest improvement over the 32K context of Gemini 1.0. It was a qualitative change in the category of problems the model could address. Tasks that previously required chunking documents into pieces, building retrieval systems, or making multiple model calls could now be handled in a single pass.
Gemini 1.5 Pro uses a Mixture-of-Experts architecture — though the specific parameter counts have not been publicly disclosed — which allows it to maintain strong performance without proportionally scaling compute costs. It handles text, images, audio, video, and code across all modalities.
Gemini 1.5 FlashReleased: May 2024 Context: 1,000,000 tokens
Flash is the efficient counterpart to Pro within the 1.5 generation. It carries the same one-million-token context window as 1.5 Pro but is significantly faster and considerably cheaper per call. For applications where maximum reasoning depth is not required but large context and strong multimodal capability are — document summarization, content analysis, customer interactions — 1.5 Flash became the practical default for developers in the second half of 2024.
Gemini 1.5 Flash-8BReleased: October 2024 Context: 1,000,000 tokens
The smallest model in the 1.5 family, still carrying the full one-million-token context window. Flash-8B is built for the highest-volume, most cost-sensitive workloads where the task is straightforward and speed and price matter most. It was the lightest Gemini option available before the 2.0 generation arrived.
Gemini 2.0 Series — Real-Time Capabilities and First Reasoning Model
Gemini 2.0 FlashReleased: December 2024 (experimental), February 2025 (stable) Context: 1,000,000 tokens
Gemini 2.0 Flash is the model that replaced 1.5 Flash as the default Gemini workhorse. The headline upgrades over 1.5 Flash are significant: it runs faster than Gemini 1.5 Pro while delivering better overall performance, supports real-time audio and video streaming for live conversational applications, and introduces native image generation capability directly within the model rather than through a separate system. It also added native tool use and code execution. In short, 2.0 Flash is faster, cheaper, and more capable than the model it replaced — the kind of generational step that shifts developer defaults almost immediately.
Gemini 2.0 Flash-LiteReleased: February 2025 Context: 1,000,000 tokens
The most cost-efficient model in the 2.0 generation. Flash-Lite is faster and cheaper than 2.0 Flash, designed for the highest-volume, simplest workloads where cost per call is the primary optimization. It replaced the 1.5 Flash-8B as the lightweight tier option.
Gemini 2.0 Flash ThinkingReleased: January 2025 (experimental) Context: 1,000,000 tokens
Google's first reasoning model — a direct response to OpenAI's o1 series. Flash Thinking does not just generate a response; it works through a problem step by step before producing its final answer, with the reasoning process visible to the user. This extended thinking produces meaningfully better results on problems requiring mathematical precision, logical chains, and scientific reasoning — the category of tasks where fast generative models consistently underperform.
Flash Thinking launched as an experimental release while Google evaluated the approach and refined the model. Its existence confirmed that Google was pursuing the same reasoning-model architecture that OpenAI had introduced with o1.
Gemini 2.0 Pro (Experimental)Released: February 2025 Context: 2,000,000 tokens
The most capable model in the 2.0 generation, with the strongest coding performance and a two-million-token context window. It launched as an experimental release on Google AI Studio and Vertex AI — available for developers and researchers to evaluate while Google continued development toward the 2.5 generation.
Gemini 2.5 Series — The Current Frontier
Gemini 2.5 ProReleased: March 2025 (preview) Context: 1,000,000 to 2,000,000 tokens
Gemini 2.5 Pro is Google's current most capable model and the one the company points to when demonstrating frontier performance. It is a thinking model — reasoning is built into the architecture rather than being an optional mode — which means it works through complex problems before answering by default.
At its release, Gemini 2.5 Pro topped several competitive leaderboards including LMArena's human preference rankings, and led on coding benchmarks that measure performance on real-world software engineering tasks. It handles all major modalities: text, images, audio, and video.
The context window of one to two million tokens positions it alongside Gemini 1.5 Pro and 2.0 Pro for tasks involving massive document collections or extended autonomous workflows. Google uses Gemini 2.5 Pro as the model powering its Gemini app at the highest capability tier.
Gemini 2.5 FlashReleased: May 2025 Context: 1,000,000 tokens
The efficiency model of the 2.5 generation, and one of the more interesting designs in the lineup. Gemini 2.5 Flash uses hybrid reasoning — thinking can be toggled on or off per request. This lets developers apply deep reasoning selectively, paying the additional latency and cost only when the task genuinely needs it, while running standard fast inference for simpler queries. It delivers the best price-performance in the 2.5 family and is strong enough on coding and reasoning tasks to compete with models that cost significantly more per call.
Gemini 2.5 Flash-LiteReleased: 2025 Context: 1,000,000 tokens
The smallest and most economical model in the 2.5 family. Flash-Lite is built for speed and volume — the 2.5 generation's answer to high-frequency automation, quick classification, and real-time interfaces where the latest generation's improvements matter but deep reasoning does not.
Part Two: The Gemma Family — Open-Weight Models for Developers
While Gemini is proprietary and managed, the Gemma family is open-weight, Apache 2.0 licensed, and built for developers who need full control — the ability to download model weights, run locally, fine-tune on proprietary data, and deploy without depending on Google's infrastructure.
Gemma Open-Weight Lineup
Model | Released | Sizes | Key Trait |
|---|---|---|---|
Gemma 1 | February 2024 | 2B, 7B | First open-weight Gemma |
Gemma 2 | June 2024 | 2B, 9B, 27B | Knowledge distillation, stronger benchmarks |
CodeGemma | April 2024 | 2B, 7B | Code-specialized |
PaliGemma | May 2024 | 3B | Vision-language, fine-tunable |
RecurrentGemma | April 2024 | 2B | Griffin architecture, memory-efficient |
Gemma 3 | March 2025 | 1B, 4B, 12B, 27B | Multimodal, 128K context, 140+ languages |
Gemma 4 | 2026 | E2B, 26B-A4B, 31B | MoE architecture, 256K context, reasoning |
Gemma 1 — The Foundation
Released: February 2024 Sizes: 2B and 7B parameters License: Apache 2.0
The first Gemma release established the open-weight lineage derived from Gemini research. At 2B and 7B parameters, both models punched above their weight class on standard benchmarks at launch. The instruction-tuned variants were immediately useful for building applications, while the base models gave researchers a flexible starting point for fine-tuning. Gemma 1 proved that Google's research could produce genuinely competitive open models — not just proprietary ones.
Gemma 2 — Knowledge Distillation Upgrade
Released: June 2024 Sizes: 2B, 9B, and 27B parameters License: Apache 2.0
Gemma 2 used knowledge distillation — a technique where a larger teacher model trains a smaller student model, transferring its capabilities more efficiently than training from scratch — to produce models that outperformed their parameter count. The 27B variant in particular demonstrated performance competitive with models two to three times its size. Gemma 2 also used an interleaved local and global attention architecture to handle longer sequences more efficiently. This was the model that made Gemma genuinely viable for production workloads that previously would have required much larger systems.
CodeGemma — The Code Specialist
Released: April 2024 Sizes: 2B (code completion), 7B (instruction-tuned) Languages supported: Python, JavaScript, Java, Kotlin, C++, C#, Rust, Go
CodeGemma is a Gemma variant fine-tuned specifically on code from GitHub. The 2B version is optimized for code completion — the fast, inline suggestions developers see as they type. The 7B instruction-tuned version handles broader coding tasks: writing functions, explaining code, debugging, and answering programming questions. For developers building coding assistants or code analysis tools who want an open-weight model they can customize for their specific codebase or language environment, CodeGemma is the practical starting point.
PaliGemma — The Vision-Language Model
Released: May 2024 Parameters: 3B Architecture: PaLI-3 vision encoder plus Gemma language model
PaliGemma combines a vision encoder from Google's PaLI-3 model with a Gemma language decoder, creating a 3B parameter vision-language model designed specifically for fine-tuning rather than out-of-the-box use. It handles image captioning, visual question answering, object detection, and image segmentation — but its real value is as a starting point. Teams working on specialized vision tasks — medical imaging, satellite data interpretation, industrial inspection — can fine-tune PaliGemma on their domain-specific data with modest compute requirements.
RecurrentGemma — The Memory-Efficient Variant
Released: April 2024 Parameters: 2B Architecture: Griffin (recurrent and attention hybrid)
RecurrentGemma uses the Griffin architecture developed by Google DeepMind — a hybrid that combines recurrent neural network processing with selective attention mechanisms. This design is more memory-efficient for long sequences than pure transformer architectures, making it suitable for deployment scenarios where memory is constrained. At 2B parameters, it is primarily a research and experimentation model that demonstrates an alternative architectural path to transformer-based approaches.
Gemma 3 — The Multimodal Open Model
Released: March 2025 Sizes: 1B, 4B, 12B, and 27B parameters Context window: 128K tokens License: Apache 2.0
Gemma 3 was a significant step forward for the open-weight family on three dimensions simultaneously. First, multimodality — the 4B, 12B, and 27B variants all accept images as input alongside text, bringing vision capability into the open-weight lineup. Second, context — the 128K token window covers the vast majority of real-world document lengths. Third, language coverage — all variants support over 35 languages out of the box, with pre-training across more than 140 languages.
The 1B model is small enough for on-device deployment and edge applications. The 27B model outperforms considerably larger models on several benchmarks, demonstrating that Google's research into intelligence-per-parameter was paying dividends across the Gemma lineup as well as Gemini.
Gemma 4 — The Current Open-Weight Frontier
Released: 2026 Variants: E2B (2.3B effective), 26B-A4B (MoE, 3.8B active), 31B (Dense) Context window: 128K (E2B), 256K (26B-A4B and 31B) License: Apache 2.0
Gemma 4 brings Mixture-of-Experts architecture into the open-weight family for the first time with the 26B-A4B variant — 25.2B total parameters but only 3.8B active per token, delivering large-model knowledge at near-4B cost and latency. All three variants include built-in reasoning mode, native function calling, and multimodal text plus image input. The 31B dense model scores 39 on the Artificial Analysis Intelligence Index, against a class median of 15 for models in the 4B to 40B open-weight category. Gemma 4 is now available on Amazon Bedrock as a fully managed deployment option for teams that want open-weight flexibility without self-hosted infrastructure.
Part Three: Specialized Domain Models
Beyond the general-purpose Gemini and Gemma families, Google DeepMind has built some of the most consequential AI systems in specific domains. These are not general chatbots — they represent frontier AI performance on problems that matter enormously in the real world.
AlphaFold 3 — Protein and Molecular Structure Prediction
Released: May 2024 Access: AlphaFold Server (free for non-commercial research)
AlphaFold 2, released in 2020, solved one of biology's most significant long-standing problems: predicting the three-dimensional structure of proteins from their amino acid sequences. The impact was immediate and substantial — researchers gained access to structural predictions for hundreds of millions of proteins that would have taken decades to solve experimentally.
AlphaFold 3 extends that capability across the full range of biological molecules. Where AlphaFold 2 focused on proteins, AlphaFold 3 handles DNA, RNA, ligands, and small molecules alongside proteins — and critically, it models how these different molecules interact with each other. Drug discovery, in particular, depends on understanding how a candidate drug molecule binds to a target protein. AlphaFold 3 can model that interaction directly. The system is available through the AlphaFold Server at no cost for non-commercial research.
AlphaCode 2 — Competitive Programming
Released: December 2023 Built on: Gemini
AlphaCode 2 tackles competitive programming — the category of algorithmic problems that appear in contests like Codeforces and IOI, where solving them requires genuine mathematical creativity rather than pattern-matching to known solutions. In evaluations on Codeforces problems, AlphaCode 2 scored at the 85th percentile of human competitors — solving problems that would stump most professional software engineers. It uses Gemini as its foundation and applies a search process to generate and filter candidate solutions, tackling problems that the original AlphaCode 1 could not handle.
MedPaLM 2 — Medical Question Answering
Released: 2023
MedPaLM 2 was the first AI system to achieve expert-level performance on the USMLE (United States Medical Licensing Examination) — the standardized tests that practicing physicians must pass. Medical question answering at this level requires not just factual recall but clinical reasoning, understanding of edge cases, and integration of multiple pieces of information. MedPaLM 2 demonstrated that AI could match physicians on these assessments, which has significant implications for medical education, clinical decision support, and access to medical expertise in underserved settings.
MedGemini — Healthcare AI Built on Gemini
Released: May 2024
MedGemini is a Gemini-based model specifically trained and evaluated for healthcare applications. It handles medical imaging — interpreting X-rays, pathology slides, and other diagnostic images — alongside clinical notes and medical question answering. In evaluations, MedGemini reached state-of-the-art performance across multiple medical benchmarks. It represents the application of Gemini's multimodal capabilities to a domain with significant data complexity and high stakes for accuracy.
Imagen 3 — Text-to-Image Generation
Released: 2024 Available in: Gemini app, Vertex AI, Google products
Imagen 3 is Google's most capable text-to-image generation model. Compared to its predecessors, it produces significantly better detail, richer and more accurate lighting, fewer visual artifacts, and more faithful adherence to complex prompts. It powers image generation features across Google's consumer and enterprise products. For developers, it is accessible through Vertex AI as part of Google Cloud's AI portfolio.
Veo 2 — Video Generation
Released: December 2024 Available in: VideoFX, Vertex AI
Veo 2 generates high-definition video from text descriptions, with output quality up to 4K resolution. Its distinguishing capability is physics understanding — the model has learned to generate scenes where objects move, interact, and behave in physically plausible ways, which has been a persistent failure mode for video generation systems. It supports various visual styles and durations. Veo 2 is Google's direct competitor to OpenAI's Sora and represents one of the most capable text-to-video systems available through a commercial provider.
Lyria — Music Generation
Released: 2024 Available in: MusicFX Developed by: Google DeepMind in collaboration with YouTube
Lyria generates high-quality music across genres, styles, and instruments from text descriptions. Unlike earlier music generation systems that produced audio clips with obvious synthetic characteristics, Lyria produces music with natural dynamics, instrumental interplay, and stylistic coherence. It is accessible through MusicFX and represents Google's capability in audio generation alongside Gemini's text-and-image work.
Part Four: Foundational Models
These are the models that shaped the current landscape. They are not the most capable systems today, but understanding them explains why modern AI systems work the way they do.
BERT — The Transformer That Changed Everything
Released: October 2018 Developer: Google Research License: Open source
BERT was not Google's first language model, but it was the one that transformed how the entire field approached natural language processing. The key innovation was bidirectional training — instead of reading text left to right, BERT learned to understand words in the context of everything around them, both before and after. This produced dramatically better representations of meaning.
Google open-sourced BERT immediately, and its impact on research and applications was almost instantaneous. Today, BERT or its derivatives power core components of Google Search, and thousands of downstream models have been built on top of its architecture. BERT established the pre-training and fine-tuning paradigm that every modern language model follows.
T5 — Text-to-Text Transfer Transformer
Released: 2019 Developer: Google Research License: Open source
T5 unified the way language models handled different tasks by converting everything — translation, summarization, classification, question answering — into the same text-in, text-out format. Rather than training separate specialized models for each task, T5 demonstrated that a single model architecture could be applied consistently across all of them. This simplification had profound implications for how researchers thought about training and evaluating language models.
LaMDA — The Conversation-First Model
Released: 2021
LaMDA (Language Model for Dialogue Applications) was built specifically for open-ended conversation — the kind of free-flowing, contextual dialogue that general language models handled poorly. It powered the earliest prototypes of what would become Google Bard. LaMDA was notable for generating genuine controversy in 2022 when a Google engineer publicly claimed the model was sentient — a claim Google and the broader AI research community rejected. Its architecture was later superseded by PaLM 2, but LaMDA represents an important phase in Google's path toward conversational AI.
PaLM — The 540 Billion Parameter Landmark
Released: April 2022
PaLM (Pathways Language Model) used Google's Pathways infrastructure — a system for training large models efficiently across many chips — to reach 540 billion parameters. At its release, it demonstrated state-of-the-art performance on hundreds of language tasks and showed strong few-shot learning ability: the capacity to solve new problems from just a handful of examples rather than requiring extensive fine-tuning. PaLM established the scale and approach that led directly to PaLM 2.
PaLM 2 — Multilingual and Reasoning Focused
Released: May 2023 Size tiers: Gecko, Otter, Bison, Unicorn (from smallest to largest)
PaLM 2 improved on PaLM primarily in three areas: multilingual capability across more than 100 languages, coding performance, and reasoning. It powered Google Bard through most of 2023 and was deployed across Google Workspace AI features including Smart Compose, Smart Reply, and summarization tools. PaLM 2's four size tiers — named after animals — gave developers and Google's product teams a range of cost and performance options before the Gemini family took over. It has since been superseded by Gemini across all major applications.
How Context Windows Evolved Across Gemini Generations
One of the clearest ways to track Gemini's development is through the context window — the amount of information the model can process at once.
Generation | Model | Context Window |
|---|---|---|
Gemini 1.0 | Ultra, Pro, Nano | 32K tokens |
Gemini 1.5 | Flash-8B, Flash, Pro | 1,000,000 to 2,000,000 tokens |
Gemini 2.0 | Flash-Lite, Flash, Pro | 1,000,000 to 2,000,000 tokens |
Gemini 2.5 | Flash-Lite, Flash, Pro | 1,000,000 to 2,000,000 tokens |
Gemma 3 | 1B to 27B | 128K tokens |
Gemma 4 | E2B to 31B | 128K to 256K tokens |
The jump from 32K tokens in Gemini 1.0 to one million tokens in Gemini 1.5 Pro was not incremental — it was a fundamental change in what tasks the model could tackle without external retrieval systems.
Gemini vs Gemma: When to Use Which
The most common source of confusion in Google's model lineup is the relationship between Gemini and Gemma. They are related but built for different situations.
Dimension | Gemini | Gemma |
|---|---|---|
Access | API via Google AI Studio and Vertex AI | Download weights directly, self-host |
License | Proprietary | Apache 2.0 open-weight |
Fine-tuning | Limited, through Google's tools | Full fine-tuning on any data |
Data privacy | Data processed on Google infrastructure | Fully private if self-hosted |
Context window | Up to 2M tokens | Up to 256K tokens |
On-device | Nano variants only | Most sizes suitable for local deployment |
Best for | Production apps, enterprise, maximum capability | Custom deployments, regulated industries, research |
The practical rule: if you need maximum capability, long context, and do not need to own the model weights, Gemini is the answer. If you need full control over the model, the ability to fine-tune on proprietary data, or deployment in an environment where data cannot leave your infrastructure, Gemma is the right choice.
Which Google AI Model Should You Actually Use?
For most conversational, analytical, and coding tasks at production scale, start with Gemini 2.5 Flash — it balances capability and cost with the option to enable reasoning when needed.
For the hardest reasoning, complex coding, or frontier research tasks, use Gemini 2.5 Pro — Google's current most capable model.
For real-time audio and video applications or the highest-volume everyday tasks at low cost, Gemini 2.0 Flash handles both well.
For open-weight deployment where you need to own and customize the model, Gemma 3 27B or Gemma 4 31B are the current strongest options — with Gemma 4's MoE variant (26B-A4B) offering large-model knowledge at small-model cost.
For code-specialized open-weight work, CodeGemma 7B is the fine-tuning starting point.
For vision-language fine-tuning on domain-specific data, PaliGemma at 3B provides a strong foundation.
For protein structure and molecular interaction prediction, AlphaFold 3 remains the state of the art.
For video generation, Veo 2 is available through Vertex AI and VideoFX.
For image generation integrated into Google's product ecosystem or enterprise infrastructure, Imagen 3 is the current standard.
Final Takeaway
Google's AI model portfolio is the broadest of any major AI organization. From BERT — the 2018 research contribution that reshaped how natural language processing works — to Gemini 2.5 Pro at the current frontier, the lineage runs through decades of genuine research investment.
For most developers and enterprises, the practical choice lives in the Gemini 2.5 tier for maximum capability and the Gemma 3 or 4 family for open-weight flexibility. The specialized models — AlphaFold, Veo, Imagen, MedGemini — are not alternatives to Gemini; they are purpose-built systems that handle domains where a general-purpose model is not the right tool.
The clearest signal of where Google's AI strategy is heading is the convergence between Gemini and Gemma: the same architectural innovations appearing in both families, one proprietary and managed, one open and deployable anywhere. That dual-track approach gives Google reach across both enterprise cloud customers and the developer community building independent applications.